A key feature in Wazuh is its high capacity for expansion, which allows our users to adapt its behavior to an infinite set of needs.
Our development team and the Wazuh community at large are constantly contributing to the ruleset. But at the same time, thousands of new security-relevant devices and software programs are created daily around the world. Even more, depending on each environment, users of Wazuh will have different needs and preferences to monitor the security of their environment. So the security software you use must be highly flexible while also being easy to configure.
Wazuh’s log analysis algorithm
When log messages are collected by Wazuh from the vast amount of sources relevant to an environment’s security, Wazuh’s analysisd module will determine how to react to them depending on the decoders and rules that constitute the ruleset. This ruleset can be easily personalized by adding custom rules and decoders as well as editing or excluding parts of the default ruleset if necessary.
The ruleset is analyzed using a very simple and resource efficient logic that allows the Wazuh manager to handle large amounts of log data while requiring little computing power. For every message that is ingested, it is first checked sequentially to see if it matches one by one the decoders that don’t have a specified parent. When it fulfills the conditions of any one of them the process is repeated with the decoders that have this decoder as a <parent>, and the process is then repeated until there are no more children decoders to test.
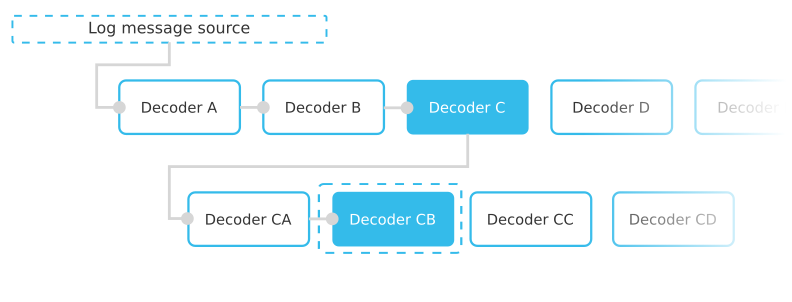
Afterwards, a very similar process is carried out with the configured rules using the extracted fields, which will determine the actions to be taken by Wazuh based on the final matching rule. The information extracted in the different fields will then be logged so they may be used in active-response scripts, integrations, and powerful filtering and visualization options on tools like Kibana or Splunk.
Dealing with dynamically structured logs
The process of matching at decoder level uses regular expressions, and as such require that the matching string have a specific structure. However many log sources will often provide information omitting parts of the log or in various orders, which would make it impractical or even impossible to create all the necessary decoders to match each one of the possible combinations in which the security-relevant data may be received.
This is where “sibling” decoders come in. Taking advantage of the simple parent-children matching logic, one can make a set of decoders that are together “parents” of themselves. The resulting effect is that when one of these decoders is matched it will also check the “sibling” decoders whilst extracting one piece of information at a time.
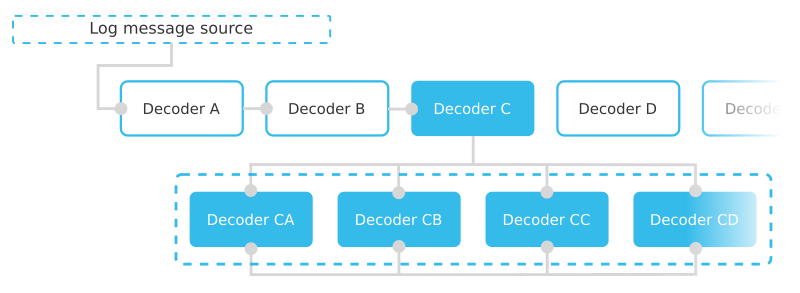
As a consequence, if the ordering of the information varies, there’s additional information or if any of the matching strings are missing, the analysisd module will still be able to extract as much information as possible from the message.
A welcome side effect of extracting information in this modular way, is that decoders become much more readable than one long regular expression string.
Sibling decoders: A practical example
Say we have a log source that provides the following log message:
2019/01/02 13:16:35 securityapp: INFO: srcuser="Bob" action="called" dstusr="Alice"
A simple decoder may be:
<decoder name="securityapp"> <program_name>securityapp</program_name> <regex>(\w+): srcuser="(\.+)" action="(\.+)" dstusr="(\.+)"</regex> <order>type,srcuser,action,dstuser</order> </decoder>
Using /var/ossec/bin/ossec-logtest we get:
**Phase 1: Completed pre-decoding. full event: 'Apr 12 14:31:38 hostname1 securityapp: INFO: srcuser="Bob" action="called" dstusr="Alice"' timestamp: 'Apr 12 14:31:38' hostname: 'hostname1' program_name: 'securityapp' log: 'INFO: srcuser="Bob" action="called" dstusr="Alice"' **Phase 2: Completed decoding. decoder: 'securityapp' type: 'INFO' srcuser: 'Bob' action: 'called' dstuser: 'Alice'
However if the log source then provides the message:
Apr 01 19:21:24 hostname2 securityapp: INFO: action="logged on" srcuser="Bob"
No information is extracted:
**Phase 1: Completed pre-decoding. full event: 'Apr 01 19:21:24 hostname2 securityapp: INFO: action="logged on" srcuser="Bob"' timestamp: 'Apr 01 19:21:24' hostname: 'hostname2' program_name: 'securityapp' log: 'INFO: action="logged on" srcuser="Bob"' **Phase 2: Completed decoding. decoder: 'securityapp'
But using modular logic with sibling decoders:
<decoder name="securityapp"> <program_name>securityapp</program_name> </decoder> <decoder name="securityapp"> <parent>securityapp</parent> <regex>^(\w+):</regex> <order>type</order> </decoder> <decoder name="securityapp"> <parent>securityapp</parent> <regex>srcuser="(\.+)"</regex> <order>srcuser</order> </decoder> <decoder name="securityapp"> <parent>securityapp</parent> <regex>action="(\.+)"</regex> <order>action</order> </decoder> <decoder name="securityapp"> <parent>securityapp</parent> <regex>dstusr="(\.+)"</regex> <order>dstuser</order> </decoder>
Both messages are then correctly decoded:
ossec-testrule: Type one log per line. Dec 28 01:35:18 hostname1 securityapp: INFO: srcuser="Bob" action="called" dstusr="Alice" **Phase 1: Completed pre-decoding. full event: 'Dec 28 01:35:18 hostname1 securityapp: INFO: srcuser="Bob" action="called" dstusr="Alice"' timestamp: 'Dec 28 01:35:18' hostname: 'hostname1' program_name: 'securityapp' log: 'INFO: srcuser="Bob" action="called" dstusr="Alice"' **Phase 2: Completed decoding. decoder: 'securityapp' type: 'INFO' srcuser: 'Bob' action: 'called' dstuser: 'Alice' Apr 01 19:21:24 hostname2 securityapp: INFO: action="logged on" srcuser="Bob" **Phase 1: Completed pre-decoding. full event: 'Apr 01 19:21:24 hostname2 securityapp: INFO: action="logged on" srcuser="Bob"' timestamp: 'Apr 01 19:21:24' hostname: 'hostname2' program_name: 'securityapp' log: 'INFO: action="logged on" srcuser="Bob"' **Phase 2: Completed decoding. decoder: 'securityapp' type: 'INFO' srcuser: 'Bob' action: 'logged on'
In conclusion, with sibling decoders, Wazuh provides the flexibility to allow its users to gather relevant information even when the source is not predictably structured as a simple regular expression would require for matching as well as providing an easier to follow modular decoder building process.
If you have any questions about this, join our Slack community channel! Our team and other contributors will help you.